该文章由【吐司创造营】直播的部分脚本编成,部分操作向和演示向内容无法用文本撰写,故推荐配合回放观看效果更佳。部分观点来源网络,如有错误欢迎指正!
本期文章对应回放为👉:BV1BZ421e7fE
概念
基本定义:将提供数据、引导机器学习的过程叫做训练,训练得到的结果叫做模型,用模型解决问题的过程叫推理。
数据集=图像+文本,图片里蕴含的"像素分布规律",解释这些不同颜色的像素点是如何排列组合形成各种事物的。
Embedding:嵌入向量的本质是一串很长的数字序列,每个数字对应一个维度,用于描述某一种向量空间里的特征。向量指一个同时具有大小和方向的量。
提示词:分解为token(机器学习里的一个最小语义单位),文本编码器会将token里的含义转换成一组拥有768个维度的词元向量 token embeddings,vae变分自编码器把向量转换回肉眼可以分辨的正常图片。
生图还原度:将提示词里的各种描述信息转换成了一个个向量然后和训练时掌握的各种规律一一对号入座。
训练方法
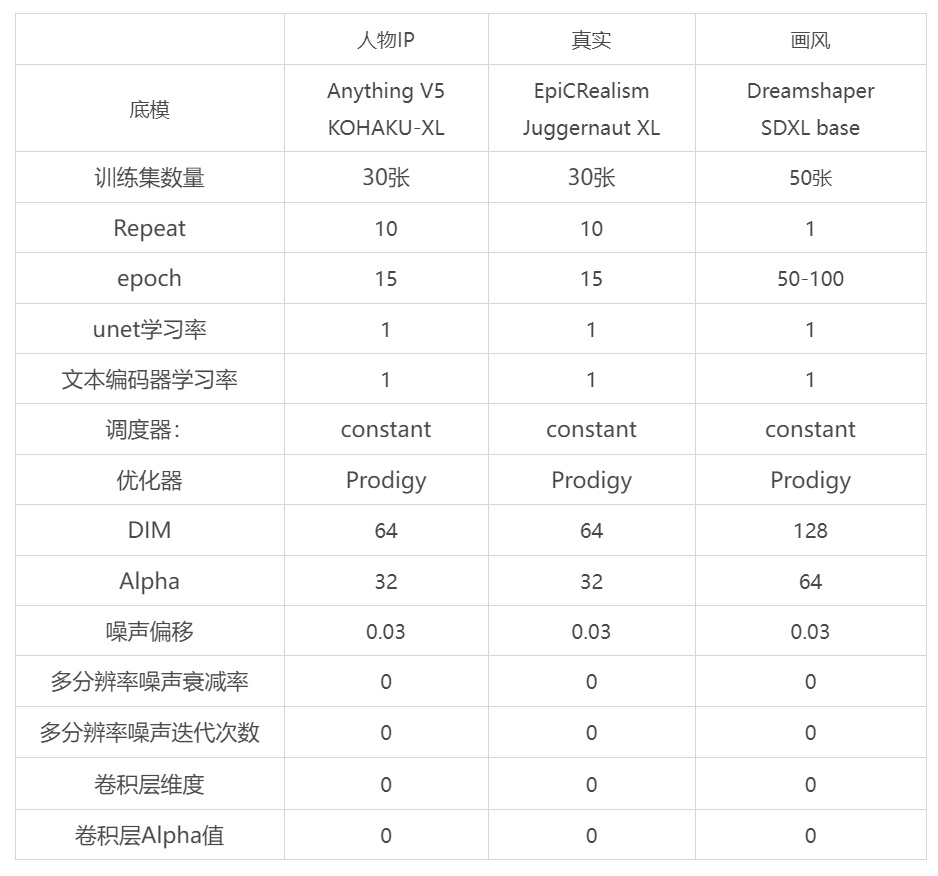
Dreambooth——Checkpoint
Lora——Lora
Textual Inversion——Embedding
正式训练流程
训练集准备:训练集注重的是质量,数量则保持在 15 -30张图片以上即可。
一个 characters 人物角色需要 10 到 50 张训练图片, styles 某种风格则需要 100 到 4000 张,某种 concepts 概念则需要 50 到 2000 张。
eg.如果是训练脸部模型,则需要照片的主体区域大部分为人脸,各个角度,多种表情,不同光线下的,清晰的脸部图片。构图简单一些,尽量少一些背景元素对前景人脸的干扰,避免重复高度相似的图像,以避免过拟合。可以适当有一两张全身像。
其他主题也是一样的考虑,训练什么,训练集的图片中的主体就突出什么。围绕不同角度,多进行取材。避免画面中其他元素的干扰。
图片预处理:让训练集更符合模型训练本身的规范,即裁剪和打标。
裁剪:SD1.5 最低512*512,SDXL 1024*1024,可以裁剪成长方形,但一定要是64x的倍数。
打标:不是越多越好,机器打标不一定100%准确,模型标签的筛选有一个非常简单好记的原则,需要什么就删除什么(绑定在模型上,不需要输入词就可以生成);触发词不能是通用词语需要是词典里没有的单词,不然会让AI产生混乱。任何你没有标注的内容,就是模型要学习的主要对象的天生内在的独有特征。风格、概念的打标不用太过于细致,调一个相对低的打标阈值。
Mixed precision混合精度:no、fp16、bf16 三个选项。此为设置训练期间权重数据的混合精度类型,用以节省 CRAM。最初,权重数据是 32位的(即在设置为 no 情况下)。fp16 是一种精度减半的数据格式,它可以节省大量 VRAM (显存)并提高速度,但效果没有 bf16 好。bf16 是 NVIDIA RTX30 系列显卡以后的版本才有的,是一种用于处理与 32 位数据相同的数字宽度的数据格式。如果你的硬件支持 bf16,最好选择它。如果 VRAM 小于 16G 的话,请选择 fp16。
Save precision储存精度:float、fp16、bf16三个选项。此为指定要保存到 LoRA 文件中的权重数据的精度。float 是 32 位,fp16 和 bf16 是 16 位。 默认值为 fp16。同样,bf16 的效果要好于 fp16,但需要硬件的支持。如果你想缩小模型的文件尺寸,该选项将起到一定的帮助(如果你通过 DreamBooth 或 Fine-tuning 方式存储模型文件为 Diffusers 格式,则设置该选项无效)。
正则化:用于避免图像过拟合的方式(见第二课)
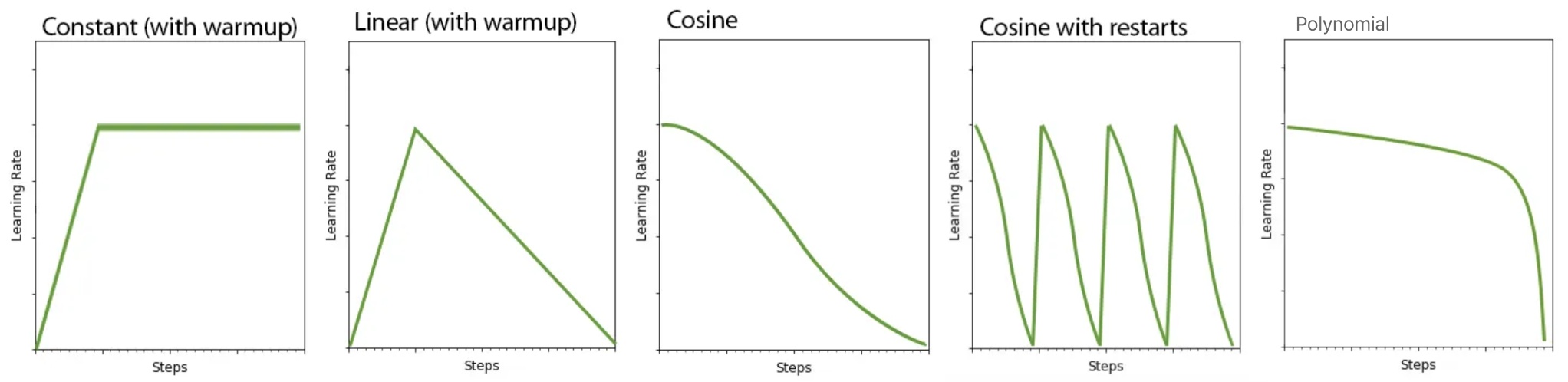
调度器:一般设置为 constant 或者 constant_with_warmup。 如果下面的 Optimizer 优化器设置为 Prodigy神童,则 Prodigy 在学习率调度器为 constant 的设置下可以很好地工作,学习率统一设置为1。如果设置为 constant_with_warmup 以配合Prodigy,则需要更多的学习步数。大约 10 % 学习率预热 LR warmup 时,可能需要一两个额外的 epoch 轮数来补偿。
LR warmup (% of steps)滑块:1~100数值选择。此为学习率预热步数,一般以总学习步数的百分比形式出现,即总学习步数的前百分之多少步为逐渐预热期。所谓逐渐预热是指学习率从0直至事先设定的最高学习率的逐渐提高过程(学习率的提高代表着学习速度的提高,即学习得越来越不细腻)。
调度程序中选择了constant_with_warmup 则设置此项,如果你的调度程序不是constant_with_warmup,则可以忽略它。默认为 10,即10%。
优化器:决定了AI如何在这个过程里把控学习的方式,直接影响到学习效果。此项默认为 AdamW8bit。优化器是确定在训练期间如何更新神经网络权重的设置。LoRA 学习最基础用的是“AdamW”(32位)或“AdamW8bit”(8位)。 AdamW8bit 使用较少的 VRAM 并且具有足够的精度,因此如果你不确定哪个更适合,请使用“AdamW8bit” 。另外,融合了Adam方法,根据学习进度适当调整学习率的“Adafactor”也经常被使用(使用Adafactor优化器时,学习率调度设置则被忽略)。 “Lion”是一个相对较新的优化器,尚未得到充分验证,据称 AdamW 更好。“SGDNesterov” 学习准确率不错,但速度较慢。DAdaptAdam 是比较稳妥的通用的选择,Prodigy 则是 Dadaptation 的升级版,适合在 SDXL 的环境,它会随着步数增加寻找最优的学习率,在训练 SDXL 的 LoRA 模型时选择它可以达到很好的结果。

学习率:AI学习这些训练集图片的强度,学习率越高,AI就更能学的进去。(学习率越大学习速度越快但学得也越粗犷,反之越细腻但效率也越低。)
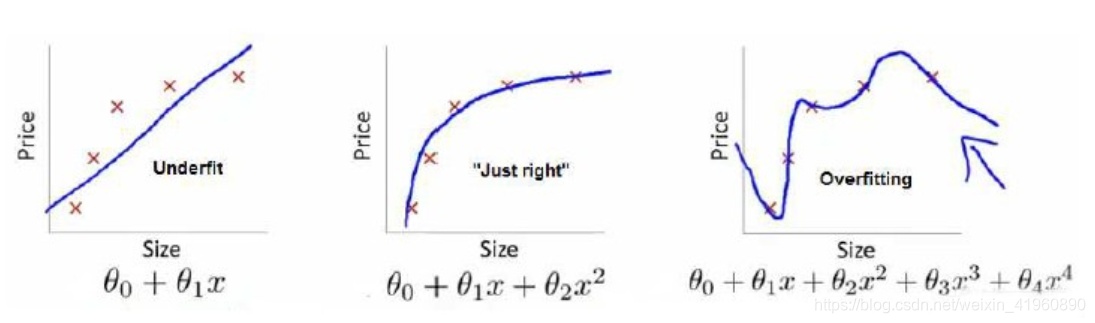
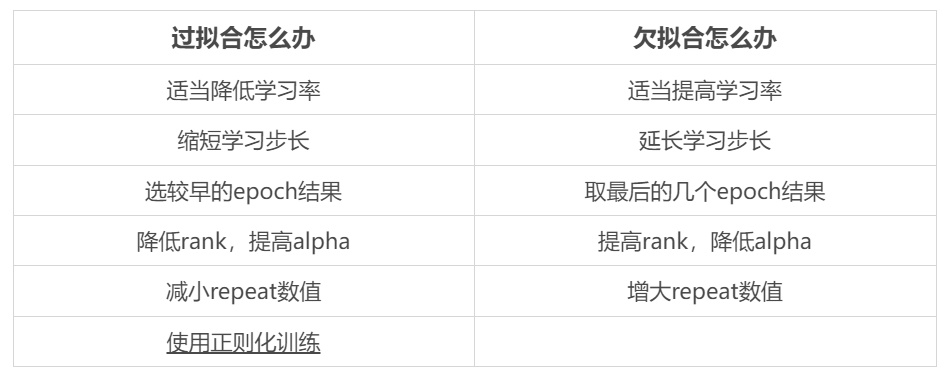
过拟合:AI过于紧密或精确的匹配训练用的数据集导致它无法良好地根据新的数据生成新的结果。
关于 Optimizer 优化器额外的解释和建议
Lion 的训练结果经常给人一种很奇特的感觉,比如你要想训练一个有着白色头发的角色,结果训练出来的模型的头发却呈现出了彩虹色的混乱效果,于此同时用其他优化器训练同样的训练集则会得到正确的白色头发效果,这足以证明Lion 可能存在某种不一样的地方,会为模型添加某些独特的元素,但现在尚无人能总结出确切的规律。 Lion 的学习速度相当快;
AdaFactor 在训练时需要很长的时间,每训练一步时间都很长。它可能更适合风格或概念类的模型这种需要更多步数的训练;
DAdaptation 目前已经被重命名为 DAdaptAdam。它是一种自适应的优化器,即它会动态地自动地调整训练中的数值,省去你手动操作繁琐工作。 只要训练集本身没有问题,它通常会让你以最少的时间付出给出非常好的结果。目前为止,它应该算是最好用的优化器了。 DAdaptation 需要特定的参数设置才能起作用: --optimizer_args “de Couple=True” “weight_decay=0.01” “betas=0.9,0.999” 。 Scheduler 调度程序必须设置为 constant 常量。 在使用 DAdaption 时,很多网上提供的经验显示 U-Net 和 TE 的学习率似乎最好都是 1.0,这个大家可以自己去尝试看看。不过,有一个问题需要注意, DAdaptation 对 VRAM 的需求很重。它在 batch size 为 1 (512x512) 的情况下,使用 6.1GB 的 VRAM,因此 6GB VRAM 用户将无法使用它。 在这种情况下,AdaFactor 可能是一个较好的替代方案。在尝试了各种 Alpha 值来对应 Dadaptation 之后,似乎 Alpha 1 和 Alpha 64( Network Rank (Dimension) 为 128)。建议将 Alpha 的值保持在 Network Rank (Dimension) 的 1 到一半之间(也就是说 Rank 为 128,则 Alpha 的值设置为 1~64。如果 Rank 为 32,则 Alpha 的值设置为 1~16);
Prodigy 可是被视为 DAdaptation 的升级版本,因此它与 DAdaptation 一样, DAdaptation 的所有属性和注意事项也同样适用于 Prodigy,VRAM 的使用率和训练速度大致也相同,设置也非常相似。同样的,Prodigy 具有自适应能力,可以随时自动调整数值以优化训练,似乎调整起来比 Dadaptation 更精准。 Prodigy 可以用于 SDXL 的 LoRA 训练和 LyCORIS 训练。在少量的测试中,我们发现在使用已经训练成功的 LoRA 所配套各种参数和训练集的情况下,把 DAdaptAdam 替换成 Prodigy 可以得到更好的结果,进一步的确认还需要之后大量的训练实验来确定。尽管在之前的很多次训练尝试中,我们已经能够确认 DAdaptAdam 是目前为止最好用的优化器,但是这不妨碍它的升级换代产品 Prodigy 在未来成为更优秀的优化器的可能性,让我们拭目以待。Prodigy 可以设置如下的 optimizer arguments 优化器参数:--optimizer_args “decouple=True” “weight_decay=0.01” “d_coef=2” “use_bias_correction=True” “safeguard_warmup=False” “betas=0.9,0.999”;
拟合状态判断
Network Rank (Dimension) :1~1024数值选择:LoRA 网络的“秩数”或“维度”(Rank 或 DIM)。在 LoRA 神经网络中,Rank 可以粗略地指代 LoRA 网络的中间层的神经元数目。Rank 常用 4~128,不是越大越好。神经元数量越多,可以保留的学习信息越多,但学习到学习目标以外的不必要信息的可能性也会增加。一般设置为 64,再高必要性就不大了,超过了 128 之后基本不会有什么变化。如果是 32,越高的 DIM 导致越多的占用 VRAM 和越大的模型文件。此项的默认值为 8 ;dim越高,要微调的数据量就越多,进而能够容纳更复杂的概念。复杂画风,二次元复杂程度比三次元低。
如何判断rank是否合适
需要增加Rank的情况:训练集图片增加(100张以上);训练复杂概念及画风;疑似欠拟合(学不像)
需要降低Rank的情况:出现突兀细节;出图效果混乱;疑似过拟合
Network Alpha(alpha for LoRA weight scaling):越接近rank则lora对原模型权重的影响越小,越接近0则lora对权重的微调作用越显著;0.1~1024数值选择。(实际上是 1~1024 取值)这一参数的引入是为了防止保存 LoRA 时权重四舍五入为 0,即下溢。由于 LoRA 的特殊结构,神经网络的权重值往往很小,如果变得太小,可能会变得与零无法区分,这与没有学习到任何东西的结果是一样的。 因此,提出了这种方法,以使 LoRA 保持较大的权重值。在学习过程中,系统总是以恒定的速率将权重削弱一定的百分比,以使权重适当变小,但是削弱的步伐太激进则会下溢。Network Alpha 则决定了这个“权重削弱率”( weight weakening rate )。 权重削弱率是通过公式“Network_Alpha/Network_Rank”来表达的,值在 0 到 1 之间。 Network Alpha 值越小, “权重削弱率” 则越小,导致 LoRA 神经网络的权重值就会保存越大,训练的 LoRA 模型越有创造力。但是太小也不好,当到达了 Alpha 的默认值 1 时,则会与训练集风格差距太远。如果 LoRA 训练学习后的准确率不令人满意,则有可能是权重太小以至于崩溃为 0。在这种情况下,可以选择尝试降低 Alpha 值,以降低削弱率,从而增加权重值来解决。Alpha 的值应该设置得比 Rank 值小,如 Rank 的一半(适合训练人物 LoRA 模型),即 Rank 若为 64,Network Alpha 设置为 32 ,此时的情况下所使用的权重削弱率为 32/64 = 0.5 。如果 Network Alpha 和 Rank 具有相同的值,则该效果自动关闭。Alpha 不能高于 Rank 值,虽然可以指定更高的数字,但很可能会导致意外的 LoRA。另外,在设置 Network Alpha 时,需要考虑到对 LR 的影响。比如,权重削弱率为 0.5(设置 Alpha 为 32,DIM 为 64),这意味着实际 LR 仅为 LR 设置值的一半效果。一般在网络上普遍的建议是 Alpha 的值是 Rank 的一半,且尽量都为 16 的倍数。
Enable buckets : “桶”,顾名思义就是“一个桶的容器”。 LoRA 的训练集图像不必具有统一的尺寸,但不同尺寸的图像不能同时进行训练。 因此,在学习之前,需要将图像按照大小分类到不同的“桶”中。尺寸一样图片放在同一个桶中,尺寸不同的图片放在不同的桶中。默认为勾选开启,即系统会自动把不同尺寸的图片放在不同的“桶”中。如果训练集的图像原本尺寸相同,你便可以关闭此选项,但保持打开状态并不会有任何影响;此选项,使得在准备训练集阶段特地将图片尺寸手动剪裁为 512*512、或 512*768 等等这样的工作变得毫无意义。因为,通过bucket “桶”这个概念可以很好地保留不同尺寸的图像,节省了事先准备的时间,更重要的是保留了图片中应有的细节。
Weights(权重)、Blocks(块)、Conv( Convolutional Neural Network,或CNN,卷积神经网络),这三个子标签是 U-Net 中每个块的 learning weight 学习权重和 Rank 秩的设置。从U-Net 网络结构图中可以看到,U-Net 总共由 25 个 block “块”(或称为“层”)组成:12个 IN 块、1个 MID 块和12个 OUT 块。这是 U-Net 网络的标准结构。如果你想改变每个块的学习率权重,你可以在这里单独设置。选择这三个中的任意一个,下面的设置区域将显示相应设置内容。这些设置适用于高级用户属于更细腻的设置。一般情况下是不需要的,如果你确定了解这些细节,并能对微调这些细节十分了解,再对此区域进行设置。
Blocks: Block dims/Block alphas:在这里,你可以为 U-Net 网络的25个块中的每一个设置不同的 Rank(DIM)值和 Alpha (Network Alpha)值:IN 0~11、MID 和 OUT 0~11。(通常 Rank 较高的块则可以容纳更多的信息。)此处需要指定 25 个数字,即对应 U-Net 中的25个块,为每个块都要指定一个数值。但由于 LoRA 是将 Attention 块作为学习目标的,而 Attention 块并不存在于 IN0、IN3、IN6、IN9、IN10、IN11、OUT0、IN1 这些块中,因此这 25 个数字中的第 1、4、7、11、12、14、15 和 16 的块在学习过程中将被忽略。尽管如此,你仍需要填写出全部的 25 个数字,以“,”半角逗号分割。(确实,此设置的用户界面不够友好,希望以后这个设置能更好用一些)此设置适用于高级用户。 一般情况下,你可以在此处留空。 如果未指定,则 Network Rank(DIM)和 Network Alpha 处设置的值将应用于所有25个块。
Conv: Conv dims, Conv, alphas:LoRA 针对 Attention 注意力块进行训练,Attention 中有一个 Conv 卷积神经网络(Convolutional Neural Networks, CNN) ,它也是通过额外的学习进行更新的。 其中使用的“过滤器”的大小是 1x1 正方形。另一方面,除了 Attention 之外的一些块(Res、Down 块)和 OUT 中的一些 Attention 块使用的是 3x3 “过滤器”进行卷积。 本来这些块并不是 LoRA 的默认 学习目标,但是通过指定这个参数,Res 块的 3x3 卷积也可以作为学习目标。因此,由于学习目标的数量增加了,便可以进行更精确的 LoRA 学习。设置方法,同之前的 Blocks: Blocks dims, Blocks alphas ,也需要设置 25 个值,以“,”半角逗号分割。同样,此设置适用于高级用户。 一般情况下,你可以在此处留空。如果未设置,则 Conv 不进行学习。
Clip skip :0~12 数值。Stable Diffusion 使用 “CLIP” 来进行提示词的文本的数字化编码。CLIP 也是一种深度神经网络,它由 12 个相似的层组成。文本(实际上是 token)最初通过这 12 个层转换为数字序列的表达,即向量形式的表达。在第 12 层,即最后一层输出出来的向量则被发送到 U-Net 网络中的 Attention 块进行处理。根据经验:如果你选择基础模型是真实质感的,最好选择 Clip skip= 1,如果选择的基础模型是绘画与动漫质感的,最好选择 Clip skip= 2。
Noise offset type: Original/Multires。噪点偏移类型。此处用于指定在向训练图像添加额外噪点时使用哪种 offset 偏移方法。默认为 Original。 Multires 则以稍微复杂的方式添加噪点。复杂一点的噪声将更有利于训练出能生成整体更明亮或更昏暗的图像的模型。Stable Diffusion 有一个大多数人都没有注意到的有趣的小瑕疵。如果你试图让它生成特别暗或特别亮的图像时,它几乎总是生成总亮度的平均值相对接近于 0.5 的图像(一个完全黑色的图像是 0,一个完全白色的图像是 1)。这是由 Stable Diffusion 模型的噪点预测器的本质所决定的。所以接近办法也自然地是在噪点预测环节进行调整,即添加某些额外的噪点,即 Noise offset 噪点偏移。
Noise offset : recommended values are 0.05~0.15 :这是当噪点补偿类型选择为 Original “原始”时的附加选项。 如果你在此处输入大于 0 的值,则会添加额外的噪点。 设置为 0 ,根本不添加噪声。设置为 1 增加了强烈的噪音。有报道称,添加约 0.1 的噪声可以使 LoRA 的颜色更加鲜艳。 默认值为 0。
Multires noise discount :recommended values are 0.8. For LoRAs with small datasets, 0.1-0.3 :0~1 数值。与多分辨率噪点迭代选项结合使用。 该值用于在一定程度上减弱各分辨率下的噪点量。 0 到 1 之间的值。数字越小,噪点越弱。 衰减量根据分辨率而变化,并且低分辨率的噪点被衰减得更多。默认值为 0,通常建议 0.8,如果训练图像较少,建议将值降低到 0.3 左右。
Multires noise iterations :enable multires noise (recommended values are 6-10) : 0~64 数值。当噪点补偿类型选择 Multires “多分辨率”时,则展示该设置项。 Multires “多分辨率”会产生多种分辨率的噪点,并将它们加在一起以创建最终的附加噪点。如果你在此处输入大于 0 的值,则会添加额外的噪点,数值则代表分辨率噪点的种类的数量。默认为 0,为 0 时不添加额外的噪点。 建议设置为 6 ~10 中的数值。
进程中如何判断LORA的完成度
loss值:越低说明拟合程度越高,0.08左右最好。
可用于吐司在线训练工作台参数